
LSTM
LSTM和RNN的区别
RNN存在的问题:
RNN对所有信息全部接收,记忆机制没有重点
RNN中的新信息会强制覆盖旧信息,很久之前的记忆只会占用当前记忆的很小一部分,无法对长期记忆进行有重点的处理
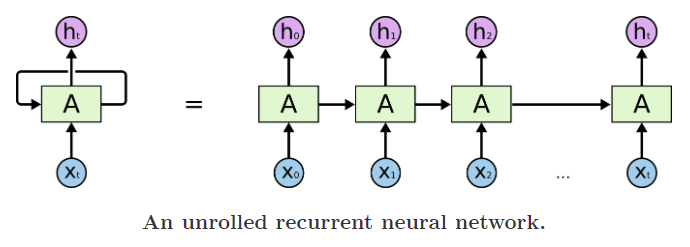
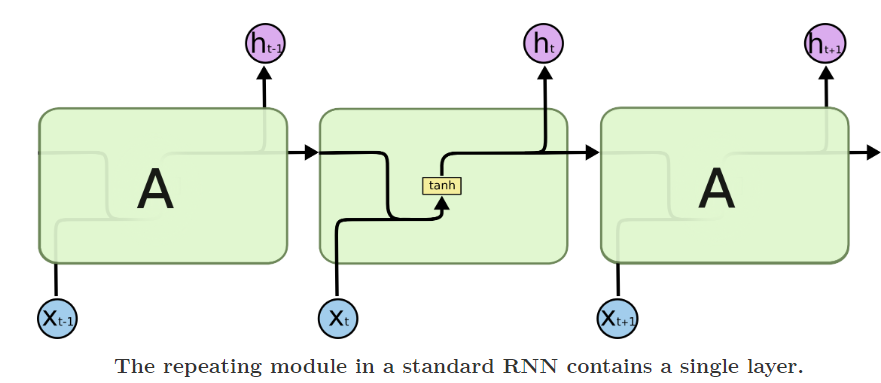
LSTM(右)与RNN的主要区别
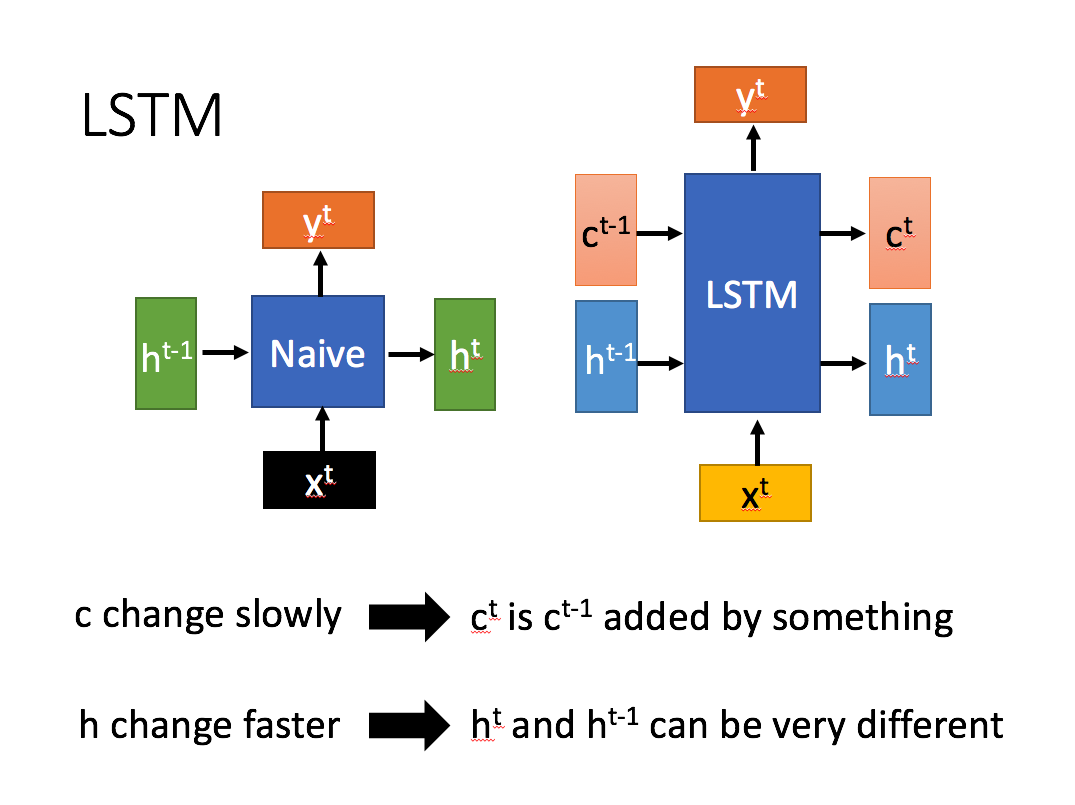
LSTM的介绍:
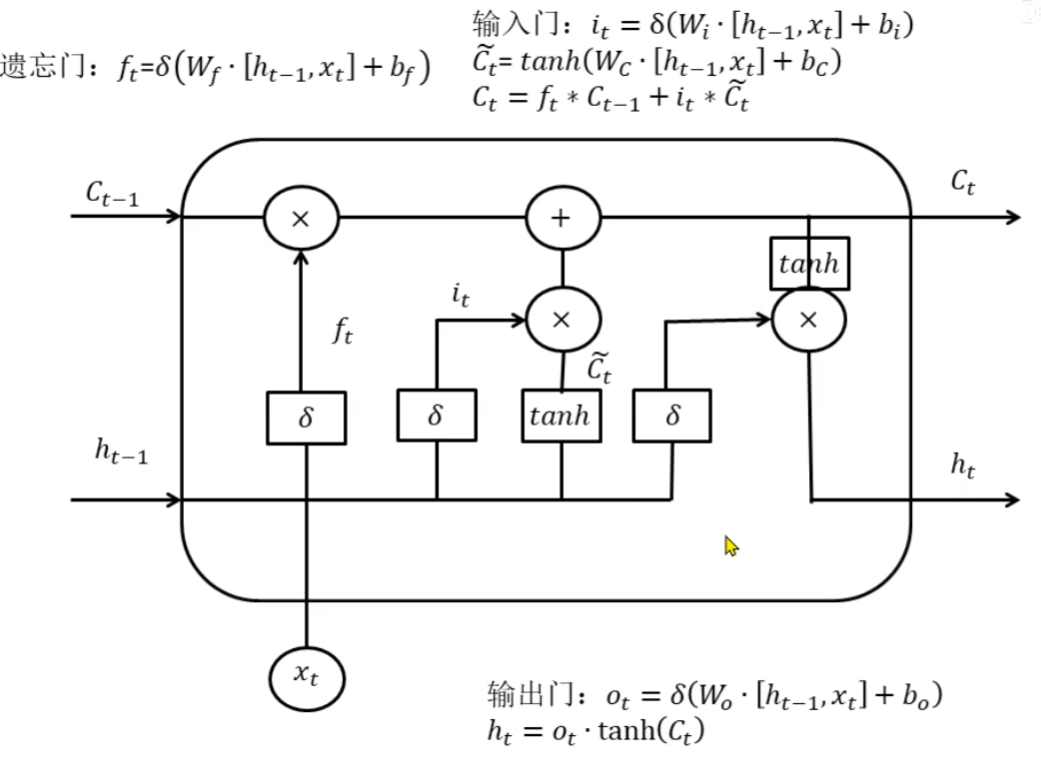
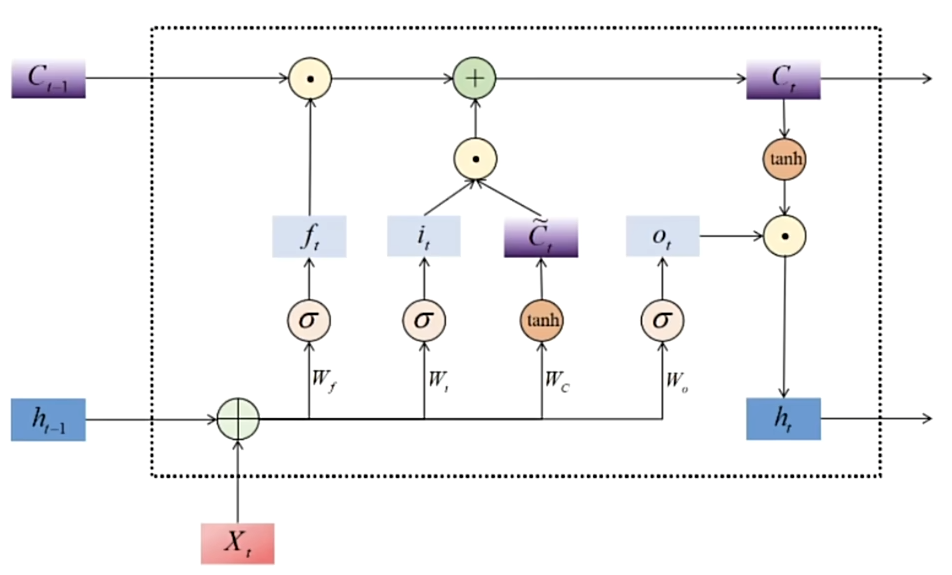
Memory Cell
LSTM依然是一个循环神经网络,LSTM设置了两个关键变量:
· 主要负责记忆短期信息、尤其是当前时间步信息的隐藏状态h
· 主要负责长期记忆的细胞状态C
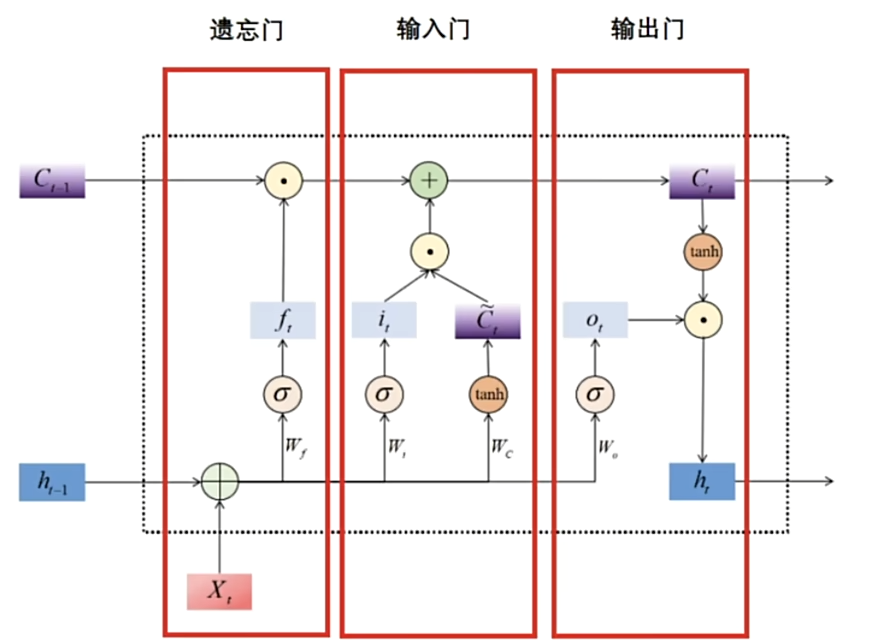
Memory Cell细分为:
· 帮助循环网络选择遗忘多少历史信息的遗忘门(forget gate)
· 帮助循环网络选择吸纳多少新信息的输入门(input gate)
· 帮助循环网络选择出对当前时间步的预测最重要的信息,并将该信息输出给当前时间步的输出门(output gate)
LSTM 逐步解释
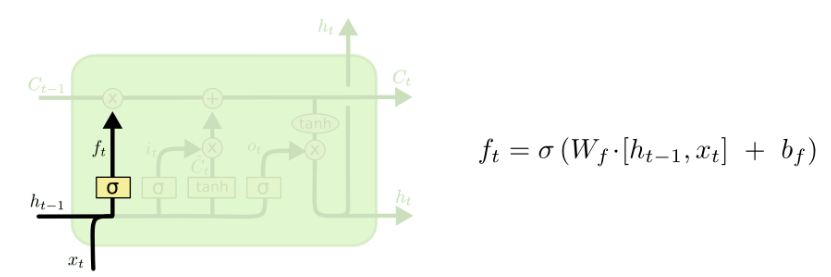
forget gate:
其数学本质就是计算一个0~1之间的遗忘比例f_t乘以上一个时间步传入的C_t-1,以此筛选掉部分旧信息。h_t-1是上一个时间步的短期信息,x_t是当前时间步的全部信息,参考h_t-1和x_t并乘以权重W_f,再通过sigmoid函数得到遗忘比例f_t。
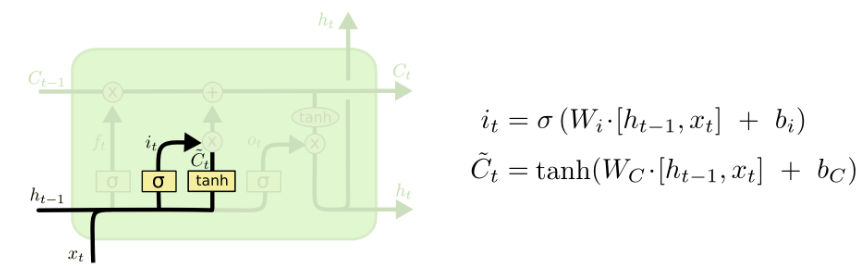
input gate:
参考h_t-1和x_t生成的筛选新信息的比例i_t,激活函数tanh生成候选信息C~_t,将两者相乘并与C_t-1合并得到新的长期记忆C_t。
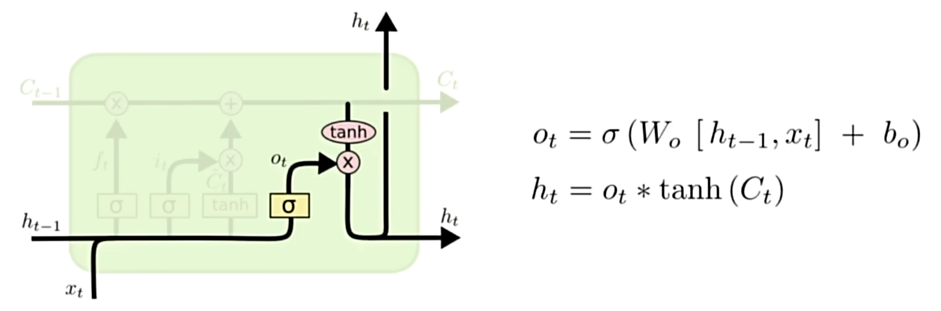
output gate:
参考h_t-1和x_t生成的一个比例值O_t,结合C_t和O_t生成当前时间步的信息h_t
LSTM在股票预测中的优势和缺陷
传统的RNN在处理长序列时会面临梯度消失或梯度爆炸的问题,而LSTM通过门控机制(遗忘门、输入门、输出门)可以有效地解决这一问题,从而能够捕捉更长期的依赖关系。
也存在一些缺陷:存在不可避免的滞后
回归算法将使用您提供的时间窗口中的值作为样本,以最大程度地减少误差。假设您正在尝试预测时间t的值。输入是以前的收盘价,即t-20到t-1的最后20个输入的时间序列窗口(假设样本输入的timestep是20)。回归算法可能会学习在时间t-1或t-2处的值作为预测值,因为这样不需要做什么就可以达到优化的误差之内了。这样想:如果在t-1值 6340,那么预测 t时刻为6340或在t + 1时为6340,从整体来看将最大程度地减小误差(因为误差是预测的很多点的误差进行汇总),但是实际上该算法没有学习任何东西,它只是复制,因此除了完成优化任务外,它基本上什么也不做
解决办法
特征工程:基于LSTM 的股票预测应用存在滞后性,其原因主要在于输入的数据均为前一天的股票价格数 据.在模型训练过程中发现,当处理这些数据的神经元权重达到很高的水平以后,训练误差会降到很小 的水平,导致训练好的神经网络算法实际上变成了“平移过去的数据”. 因此将当日的开盘价,最高价,最低价也作为数据输入,使得收盘价的权值减小,从而降低预测的滞后性。
